La modélisation des données reste un pilier incontournable des projets décisionnels, même à l’ère du Big Data et des Data Lakes. Trop souvent négligée, elle permet pourtant de garantir la qualité, la cohérence et l’exploitation des données par toutes les équipes. Aujourd’hui, de nouveaux outils collaboratifs de metadata management et de data governance offrent un cadre plus efficace que les tableurs et les diagrammes statiques. En centralisant la connaissance et en rendant le travail collectif, ils évitent le risque du « Data Swamp » et accélèrent la mise à disposition de données fiables pour l’ensemble de l’entreprise.
Pourquoi la modélisation des données reste essentielle
La modélisation décisionnelle est l’étape qui consiste à traduire dans la structure informatique les liens entre toutes les données : granularité, volumétrie, capacité de croisement, etc. Elle assure :
un système d’information robuste et performant,
une maintenance facilitée pour les équipes IT,
une exploitation fluide pour les utilisateurs métiers.
Avec l’essor desData Lakes, certaines entreprises ont cru pouvoir s’affranchir de cette discipline. Résultat : de nombreux lacs de données se sont transformés en véritables Data Swamps, difficiles à exploiter et coûteux à maintenir.
La conclusion est claire : sans gouvernance des données et sans modélisation structurée, la valeur business des données s’érode rapidement.
Des méthodes éprouvées mais souvent mal exploitées
Processus souvent individuel (un concepteur impose sa vision).
Connaissance rarement partagée ou centralisée.
Difficulté à maintenir une cohérence entre les équipes.
Résultat : les modèles reflètent parfois plus la compréhension d’un individu que la réalité métier, ce qui réduit leur valeur collaborative.
Bonne pratiques pour développer et maintenir vos data products
Dans ce guide, nous vous proposons une présentation complète afin de vous aider à faire face aux complexités du développement et du maintien de data products.
Pendant longtemps, les outils de modélisation ont freiné l’adoption d’une approche réellement collaborative :
Tableurs : absence de représentation graphique intuitive.
PowerPoint ou diagrammes statiques : impossibles à maintenir à jour.
Outils spécifiques de bases de données : cloisonnés et non collaboratifs.
Ces pratiques ne permettent pas de créer un référentiel de connaissance partagé ni de s’adapter aux évolutions rapides des données.
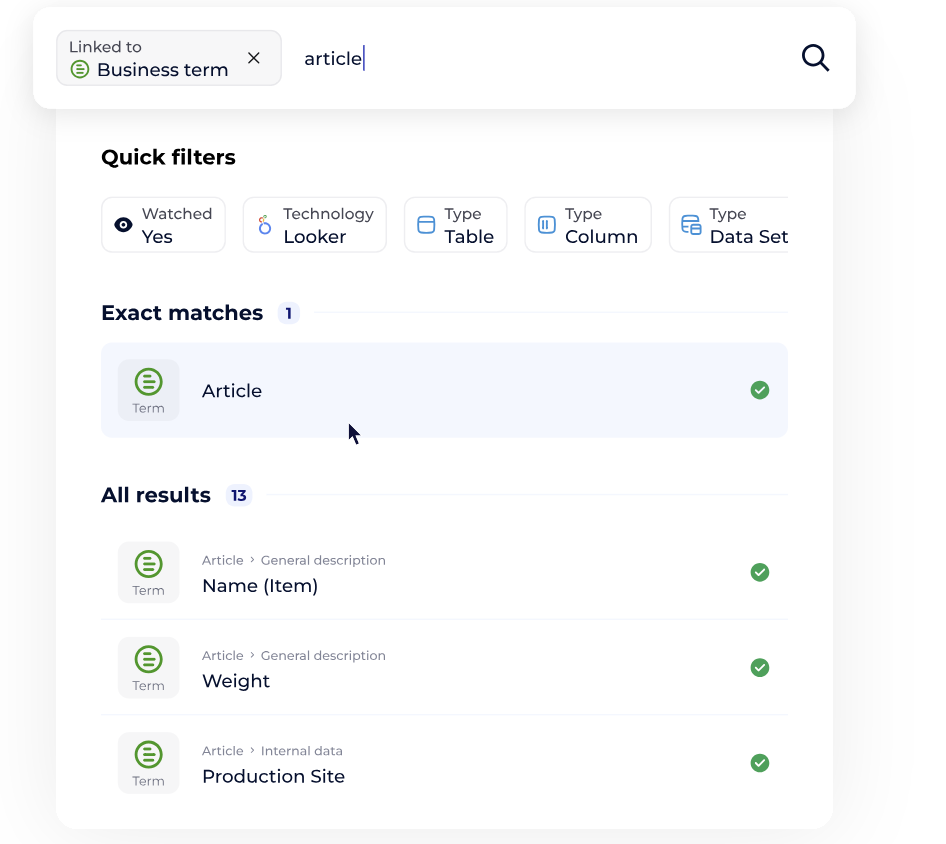
Exemple de recherche centralisée dans un référentiel de données.
Le rôle clé des outils de Metadata Management
Les plateformes modernes de metadata management apportent une réponse concrète aux limites des approches classiques. Elles permettent :
La centralisation des connaissances dans un référentiel unique.
Une collaboration en temps réel entre métiers et IT.
La traçabilité des données grâce au data lineage (origine, transformations, usages).
L’automatisation de tâches complexes comme le reverse-engineering des bases existantes.
En connectant data mapping et data modeling, elles facilitent l’intégration avec les flux ETL/ELT et les outils de restitution.
C’est précisément dans cette optique que des plateformes comme DataGalaxy positionnent la modélisation au cœur de la Data & AI Product Governance : un travail collectif, documenté et aligné avec la stratégie data globale.
Modéliser, c’est gouverner les données
La modélisation n’est plus une simple étape technique : c’est un levier de gouvernance des données. Elle garantit que toutes les équipes parlent le même langage et utilisent des définitions cohérentes.
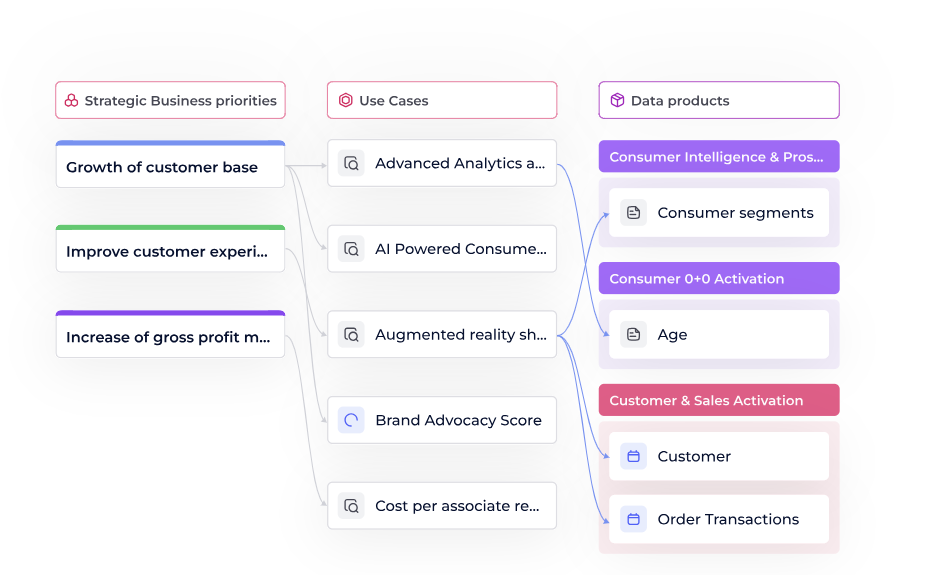
Alignement stratégique entre priorités business, cas d’usage et produits data.
Cela s’inscrit dans une approche plus large de data governance framework, qui vise à aligner les usages métiers, la conformité réglementaire (ex. RGPD, HIPAA) et les innovations technologiques.
FAQ
La modélisation est-elle encore utile avec l’IA et le Big Data ?–
Oui. Même si les technologies modernes offrent plus de flexibilité, sans modélisation, les données deviennent rapidement ingérables. L’IA elle-même a besoin de données propres, structurées et contextualisées.
Quelle est la différence entre Data Modeling et Data Mapping ?–
Data Modeling définit la structure logique et relationnelle des données.
Data Mapping établit la correspondance entre sources et cibles (utile pour les flux ETL/ELT).
Les deux sont complémentaires et doivent être alignés via un référentiel partagé.
Quels sont les bénéfices concrets d’un outil de metadata management ?–
Gain de temps grâce à la documentation automatique.
Réduction des erreurs et incohérences.
Collaboration renforcée entre équipes métiers, IT et data.
Points clés à retenir
La modélisation des données reste un pilier stratégique pour éviter les dérives des Data Lakes.
Les méthodes classiques (OLAP, Kimball) restent pertinentes, mais nécessitent des outils adaptés.
Les plateformes de metadata management apportent un référentiel collaboratif et automatisent les tâches critiques.
Modéliser, c’est aussi gouverner : cette pratique s’inscrit au cœur de la stratégie de gouvernance des données.
À propos de l'auteur: Jessica Sandifer
Tech writer
Passionnée par la transformation de la complexité des données en clarté, Jessica Sandifer est une gestionnaire de contenu expérimentée qui conçoit des histoires qui résonnent auprès d'audiences techniques et commerciales. Chez DataGalaxy, elle crée des messages de marketing de contenu et de produit qui démystifient la gouvernance des données et rendent la préparation à l'IA réalisable.
La data n’est pas un long fleuve tranquille. Au contraire : elle arrive en continu dans les entreprises, avec un flux de plus en plus rapide. Difficile de ne pas se retrouver sous l’eau sans les bons outils ! Alors comment faire pour tirer parti de cette précieuse ressource ? DataGalaxy vous présente la solution pour maîtriser ce fleuve à haut débit : le data management.
Le matin. Vous attendez patiemment votre tour pour sélectionner votre habituel petit serré noir sans sucre, en cochant les éléments de votre ToDo mentale, quand soudain :
« N’est-ce-pas ? T’en penses quoi, toi ? » Vos collègues préférés vous regardent en souriant : « le Data Hub, c’est demain, c’est maintenant, non ? T’en penses quoi ? »…
Formidable outil d’organisation et de gestion de bases de données, le Data Catalog est un élément indispensable pour votre entreprise. Comment faire pour réussir son projet de Data Catalog ? Itinéraire d’un déploiement en 5 étapes.
La gouvernance des données, ou Data Governance, est indispensable pour votre entreprise. Nous le répétons souvent : il est urgent que vous vous en empariez ! Pourquoi ? C’est simple, elle assure la bonne gestion de toutes vos données. Mais ce n’est pas tout… Zoom sur la définition de la gouvernance des données pour en comprendre les enjeux.
La semantic layer (ou couche sémantique) est une couche intermédiaire qui donne du sens aux données en intégrant des définitions métier, des règles de calcul et des relations entre les informations. En 2025, elle devient incontournable pour fiabiliser l’intelligence artificielle, réduire les erreurs et créer une véritable source unique de vérité. Contrairement à un simple data catalog, […]
Dans un contexte où la gestion des données est devenue un levier stratégique pour toutes les organisations, deux approches se démarquent : le data mesh et le data fabric. Si ces modèles partagent un objectif commun, rendre les données plus accessibles, fiables et gouvernées, leurs méthodes diffèrent profondément. Le data mesh mise sur la décentralisation […]