
Passionnée par la transformation de la complexité des données en clarté, Jessica Sandifer est une gestionnaire de contenu expérimentée qui conçoit des histoires qui résonnent auprès d'audiences techniques et commerciales. Chez DataGalaxy, elle crée des messages de marketing de contenu et de produit qui démystifient la gouvernance des données et rendent la préparation à l'IA réalisable.
Qu’est-ce que le DataOps ?
26 septembre 2025 │ Lecture : 8 mins │ Culture data par Jessica Sandifer, Tech writer

Le DataOps, contraction de data operations, est une discipline émergente à l’intersection du DevOps et de la data science.
Elle combine méthodologies agiles, automatisation et collaboration interfonctionnelle pour fluidifier l’ensemble du cycle de vie des données.
En éliminant les silos entre data engineers, data scientists, équipes IT et métiers, le DataOps permet aux entreprises de livrer des données fiables et exploitables plus rapidement.
Résultat : plus d’innovation, de meilleures décisions et une accélération des initiatives de transformation digitale.
Cet article explore en détail les fondements du DataOps, ses missions, ses rôles clés, ses bénéfices et son avenir dans un monde toujours plus guidé par la donnée.
Définition du DataOps : discipline clé de la gouvernance des données
Le DataOps est une pratique moderne de la gestion des données, située à la croisée du DevOps et de la science des données.
Essentiel à la transformation digitale et à la croissance des entreprises data-driven, il optimise la gestion du cycle de vie des données pour améliorer leur qualité.
Le DataOps vise à fluidifier la collaboration entre data engineers, data scientists et équipes IT, tout en réduisant la complexité et le coût de l’infrastructure sous-jacente. L’objectif est clair : livrer des données et des insights de manière plus rapide, plus fiable et plus continue.
En bref : Le DataOps est à la donnée ce que le DevOps est au code : une approche industrielle et agile pour fiabiliser et accélérer la livraison.
Pourquoi le DataOps est essentiel pour les entreprises data-driven
Dans un monde où la donnée est devenue un actif stratégique, les entreprises data-driven ne peuvent plus se contenter de pipelines rigides et manuels.
Le DataOps :
- Supprime les silos organisationnels entre les équipes techniques et métiers
- Améliore la qualité des données livrées
- Accélère l’innovation et les projets d’IA
Cette approche permet aux organisations de prendre des décisions plus rapides, plus fiables et plus conformes aux réglementations en vigueur comme le RGPD (Règlement général sur la protection des données) ou le CCPA (California Consumer Privacy Act).
En bref : Le DataOps est indispensable pour transformer la donnée en valeur business exploitable, tout en respectant les normes de conformité.
Les missions clés et outils du DataOps
Le DataOps ne se limite pas à quelques bonnes pratiques : il couvre l’intégralité du cycle de vie des données.
Tout commence avec la collecte et la préparation, qui incluent l’ingestion depuis différentes sources, le nettoyage pour éliminer les incohérences et la transformation pour rendre les données exploitables.
Vient ensuite la phase de développement et de déploiement, où les pipelines analytiques et les modèles de machine learning sont intégrés dans les systèmes de production.
Une fois les flux en place, l’orchestration et l’automatisation prennent le relais pour réduire au maximum les interventions manuelles et assurer une circulation fluide des données entre outils et équipes.
Enfin, la surveillance continue et l’optimisation permettent de garantir la qualité, la fiabilité et la conformité des données tout au long de leur cycle de vie.
- Collecte & préparation : ingestion, nettoyage, transformation
- Développement & déploiement : intégration de pipelines analytiques et IA
- Orchestration & automatisation : réduction des tâches manuelles
- Surveillance & optimisation continue : qualité, fiabilité, conformité
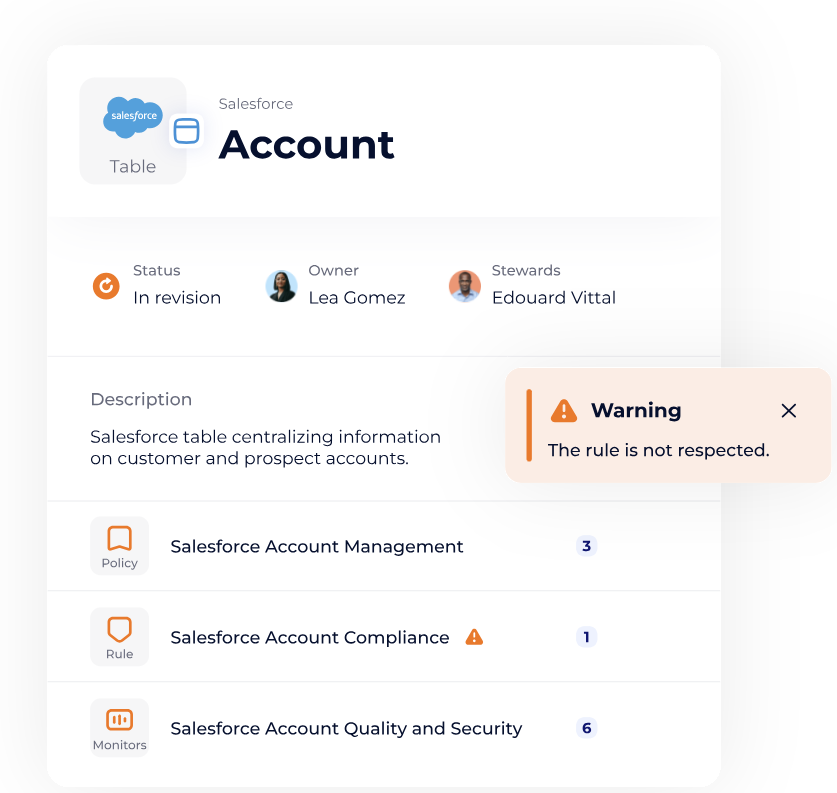
Pour atteindre ces objectifs, les organisations s’appuient sur un écosystème d’outils modernes.
Les solutions d’orchestration comme Apache Airflow, Prefect ou dbt gèrent l’automatisation des pipelines.
Les outils d’observability, tels que Monte Carlo ou Datadog, assurent la détection proactive des anomalies. Enfin, les plateformes de qualité et gouvernance comme Great Expectations ou DataGalaxy garantissent la traçabilité et le respect des normes réglementaires.
- Orchestration : Apache Airflow, Prefect, dbt
- Observability : Monte Carlo, Datadog
- Qualité & gouvernance : DataGalaxy
En bref : Le DataOps transforme la donnée en une véritable chaîne de production automatisée et contrôlée.
Bonnes pratiques pour développer et maintenir vos data products
Dans ce guide, nous vous proposons une présentation complète afin de vous aider à faire face aux complexités du développement et du maintien de data products.
Téléchargez le livre blanc
Qui pilote le DataOps ?
La réussite d’une initiative DataOps repose sur une gouvernance claire et partagée entre plusieurs profils.
Les data engineers sont les architectes techniques : ils conçoivent les pipelines ETL/ELT, assurent le stockage et veillent à la performance des flux de données.
Les data scientists, quant à eux, exploitent ces données pour développer des modèles prédictifs et analytiques, fournissant aux métiers des insights directement exploitables.
Les équipes IT et DevOps jouent un rôle tout aussi central. Elles garantissent la sécurité des environnements, la scalabilité des infrastructures et la disponibilité des services.
Enfin, la direction data (CDO, CTO) assure l’alignement stratégique : elle définit les priorités, valide les investissements et favorise la collaboration entre toutes les parties prenantes.
Cette combinaison de rôles illustre la nature profondément transversale et collaborative du DataOps : aucune équipe ne peut réussir seule, c’est l’ensemble de l’organisation qui porte la démarche.
En bref : le DataOps est une discipline collective, orchestrée par la direction et exécutée conjointement par les équipes techniques et métiers.
Les bénéfices du DataOps pour les entreprises
Adopter le DataOps, c’est passer d’une approche artisanale à une production industrielle de données. Ses bénéfices incluent :
- Rapidité : insights plus rapides, meilleure réactivité business
- Qualité : fiabilité, traçabilité et meilleure confiance dans les données
- Réduction des coûts : automatisation et rationalisation des outils
- Collaboration : suppression des silos métiers/IT
- Conformité : respect facilité des réglementations (RGPD, HIPAA, CPRA)
- Innovation : capacité à tester, itérer et déployer rapidement de nouveaux cas d’usage
Selon le Gartner Market Guide for DataOps Tools (2024), “By 2026, a data engineering team guided by DataOps practices and tools will be 10 times more productive than teams that do not use DataOps«
En bref : Le DataOps crée un avantage compétitif mesurable grâce à la rapidité, la qualité et la gouvernance des données.
DataOps vs DevOps : différences majeures
Le DataOps s’inspire du DevOps, mais leurs finalités sont différentes.
Le DevOps vise avant tout à livrer du code logiciel en continu, grâce à des cycles courts de développement et de déploiement. Le DataOps, lui, a pour mission de livrer en continu des données fiables, gouvernées et exploitables.
Les 3 KPI pour générer une réelle valeur
Découvrez rapidement les trois meilleures façons de mesurer le succès et de faire une réelle différence dans votre organisation.
Téléchargez le livre blancCette distinction est fondamentale : là où le DevOps gère essentiellement des artefacts logiciels, le DataOps doit composer avec la variabilité des données (volumes massifs, diversité des formats et des sources), les contraintes réglementaires (RGPD, HIPAA, CPRA, FISMA) et les enjeux de qualité (fiabilité, fraîcheur, traçabilité).
Autrement dit, le DataOps reprend les principes d’agilité, d’automatisation et d’intégration continue du DevOps, mais les applique à un environnement beaucoup plus complexe. Il devient ainsi un pilier complémentaire du DevOps, centré sur la donnée plutôt que sur le code.
En bref : si le DevOps est le moteur de la livraison logicielle, le DataOps est celui de la livraison de données gouvernées, essentielles à l’IA et à la transformation digitale.
Tendances et avenir du DataOps
Le DataOps évolue rapidement avec :
- IA et Machine Learning : détection automatique d’anomalies, optimisation prédictive
- Sécurité renforcée : RGPD, CPRA, FISMA et autres cadres réglementaires
- Convergence avec DevOps et Agile : vers une unification des pratiques
- Nouveaux rôles DataOps : certifications et expertise en forte demande
En bref : Le DataOps deviendra un standard incontournable de la data & AI product governance.
FAQ
- Qu’est-ce que le DataOps ?
-
Le DataOps est une pratique collaborative de gestion des données qui réunit l’ingénierie des données, l’intégration des données et les opérations afin d’améliorer la vitesse, la qualité et la fiabilité des pipelines de données. Elle met l’accent sur l’automatisation, la surveillance et la livraison continue pour garantir un flux de données fluide, de la source jusqu’à l’analyse.
- Quelle est la différence entre DataOps et DevOps ?
-
Le DevOps vise à accélérer la livraison de logiciels fiables via l’automatisation et la collaboration entre développeurs et équipes IT.
Le DataOps applique ces mêmes principes à la donnée, avec un focus sur la qualité, la traçabilité et la gouvernance.
En pratique, DataOps complète DevOps : l’un livre des applications, l’autre livre des données prêtes à l’emploi. - Quels sont les avantages concrets du DataOps pour une entreprise ?
-
Les bénéfices du DataOps vont bien au-delà de la technique :
– Accélération du time-to-insight : les données sont disponibles plus vite pour les métiers.
– Qualité renforcée : détection proactive des erreurs grâce à l’automatisation et aux pratiques de Data Observability.
– Optimisation des coûts : moins de tâches manuelles et meilleure utilisation de l’infrastructure.
– Amélioration de la gouvernance : conformité facilitée avec les réglementations comme le RGPD, le CCPA ou HIPAA.
– Culture de collaboration : décloisonnement des silos entre IT, data et métiers. - Quels sont les rôles impliqués dans une démarche DataOps ?
-
Le DataOps repose sur une gouvernance partagée :
-Les Data Engineers conçoivent et maintiennent les pipelines de données.
-Les Data Scientists exploitent ces données pour développer des modèles d’IA et d’analytique avancée.
-Les équipes IT et DevOps assurent la sécurité, la scalabilité et la disponibilité des environnements.
-Les CDO/CTO alignent la stratégie DataOps avec les objectifs business.
Ensemble, ils garantissent un flux de données continu, fiable et conforme. - Quelles tendances dessinent l’avenir du DataOps ?
-
D’ici 2026, selon Gartner, les équipes data appliquant le DataOps seront 10 fois plus productives que celles qui ne l’utilisent pas. L’avenir du DataOps sera marqué par :
– Une intégration accrue avec les pratiques Agile et DevOps.
– L’usage massif de l’IA générative pour automatiser la gestion des pipelines.
– Un renforcement de la sécurité et de la confidentialité des données.
– L’émergence de rôles spécialisés (DataOps Engineer).
Points clés à retenir
- Le DataOps combine agilité, automatisation et collaboration pour transformer la gestion des données.
- Il supprime les silos et garantit un accès rapide à des données fiables et gouvernées.
- Ses bénéfices couvrent la rapidité, la qualité, la gouvernance, la conformité et l’innovation.
- Avec l’essor de l’IA et des réglementations, le DataOps devient un levier stratégique de compétitivité
Articles liés

Le marché de la data observability : acteurs, tendances et perspectives (2025)
La fiabilité et la transparence des données sont devenues essentielles pour toutes les organisations. En 2025, le marché de la data observability connaît une croissance fulgurante, passant d’une adoption de niche à une nécessité stratégique pour les entreprises. Cet article explique ce qu’est la data observability, pourquoi elle est indispensable, les grandes tendances qui façonnent […]
Data owner vs. data steward : rôles, différences et complémentarité
Le data owner est le responsable stratégique et décisionnaire sur les données, tandis que le data steward en est le garant opérationnel de la qualité et de la conformité. Le premier définit la vision, les règles et l’usage des données dans l’entreprise ; le second veille à ce que ces règles soient respectées et que les données restent fiables. […]
Développer une culture data en entreprise (2025)
Data-centric, culture data driven, pilotage par la données… Mais de quoi parle-t-on ? Avant de parler de « gouvernance des données » (on peut le faire en même temps ?), il faut accompagner l’adoption par votre entreprise d’une culture data. Pourquoi est-elle aussi importante dans une entreprise ?
Le glossaire de données, quelles différences avec le dictionnaire ?
Au début de nombreuses réflexions d’exploitation, d’optimisation ou de valorisation des données se trouve bien souvent une démarche de cartographie.
En effet, comment bien gérer un élément dont on ne sait évaluer le volume ou la complexité ?
Comment DataGalaxy Portfolio se connecte à Jira pour structurer les initiatives data au-delà de la simple gestion de tickets
Jira est omniprésent dans les équipes data modernes. Il soutient les méthodes agiles, gère les backlogs, suit les anomalies et structure l’exécution des projets. De nombreuses organisations l’utilisent également pour piloter les tâches de gouvernance des données, les problèmes de qualité, les demandes d’accès et les initiatives analytiques. Mais voici le problème : Jira est […]
Comment DataGalaxy Portfolio se connecte à ServiceNow pour aligner la stratégie de gouvernance avec l’exécution opérationnelle
De nombreuses entreprises s’appuient sur ServiceNow pour gérer les workflows à travers l’IT, le risque, la conformité et les opérations. C’est le moteur derrière les tickets, les validations, les contrôles et les processus d’entreprise. Mais lorsqu’il s’agit de structurer la gouvernance des données à l’échelle de l’entreprise, ServiceNow n’a jamais été conçu pour définir des […]