
Le Big Data signifie pour les entreprises une mine d’informations à exploiter… Mais attention, le nombre ne fait pas tout, bien au contraire ! La mauvaise qualité des données engendre souvent des coûts, impacte l’efficacité de toute l’organisation et empêche une bonne prise de décision. Comment gérer ce problème de Data Quality ?
Pourquoi la qualité d’une base de données est critique
Pour corriger un problème, il faut pouvoir le comprendre. Difficile avec des données qui ne sont pas complètes. La plupart des entreprises ont conscience de leurs problèmes liés à la qualité de leurs données, mais ne savent pas toujours comment les résoudre. Et la plupart ne sont pas conscientes de l’ampleur de ces problèmes et surtout du coût et des dommages qu’ils représentent.
La plupart des problèmes liés aux données de mauvaise qualité sont cachés et inconnus de l’organisation. Ces difficultés constituent un des défis les plus importants et souvent sous-estimés des entreprises.
En effet, beaucoup de données dans les entreprises sont indéfinies, redondantes, non fiables, complexes ou trop volumineuses. Avec le Big Data, les entreprises ont vu dans l’accumulation de grandes quantités de données une opportunité. Mais le volume considérable, la qualité médiocre et la mauvaise gestion des données paralysent les entreprises.
Ces problèmes liés aux données forcent les entreprises à passer énormément de temps à :
- chercher les données manquantes,
- corriger les données inexactes,
- créer des solutions de contournement,
- supprimer des doublons,
- etc.
Qu’est-que la Data Quality ?
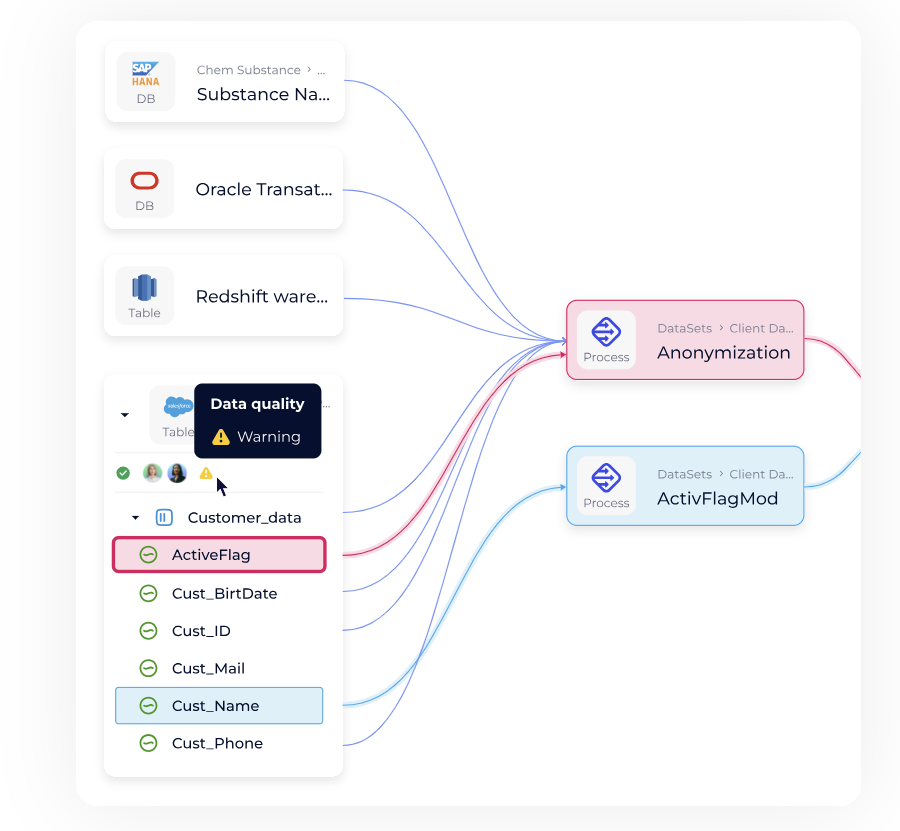
La Data Quality désigne le degré d’exactitude, de complétude, de cohérence, de pertinence et de fiabilité d’une donnée. Selon IBM, la qualité des données repose sur plusieurs piliers essentiels (exactitude, cohérence, exhaustivité, etc.), et leur amélioration continue est indispensable pour garantir une exploitation fiable des informations.
Une donnée de qualité est :
-
Correctement définie et contextualisée.
-
Mise à jour et exempte de doublons.
-
Exploitable dans la prise de décision stratégique.
Sans cette fiabilité, une entreprise navigue à l’aveugle sur des indicateurs critiques comme :
-
Les stocks,
-
Les profits et pertes,
-
La satisfaction client,
-
Les obligations réglementaires.
4 problèmes majeurs liés à la mauvaise qualité des données
#1 Les données inconnues et inexactes
Les entreprises sont mises au défi par les données inexactes, mais encore plus par leur capacité à les identifier. Comment déterminer si les résultats d’une requête sont faux, surtout si la réponse paraît correcte ?
Si un collaborateur recherche le chiffre d’affaires de sa société et tombe sur un résultat de 10 €, il aura forcément un doute sur la véracité de l’information. La donnée est sans doute inexacte. Mais si le résultat est de 200 000 €, le collaborateur ne le remettra pas en question. La donnée inexacte est utilisée et participe à créer de nouvelles données de mauvaise qualité.
Un autre cas peut se présenter lorsqu’un Data Steward cherche à nettoyer des données incorrectes. Si les données manquent de signification, de définition ou de contexte, le Data Steward se heurte à un problème, il doit « deviner » les erreurs.
Toutes ces données inexactes orientent vers de mauvaises décisions, entraînant une perte de confiance dans les données, des situations de non-conformité et d’insécurité.
#2 La perte de contexte des données
Les données d’une entreprise représentent son organisation : ses événements, ses relations, ses objets, son cycle commercial. Si les données, ou les informations sur ces données (métadonnées), sont compromises, alors c’est toute l’entreprise qui fonctionne mal.
Lorsqu’une entreprise ne met pas en place une stratégie de gouvernance des données adaptée à son organisation, les données perdent leur signification. Les noms et définitions de données manquent, sont inadéquats ou inexacts entraînant leur mauvaise utilisation.
#3 Les données non ou mal définies
La plupart des entreprises ont des données mal définies ou même indéfinies. Cette situation entraîne une perte de la signification des données. Une définition approximative de la donnée est néfaste, mais une définition trop longue et trop complexe peut elle aussi devenir « dangereuse ».
Mais lorsque les données sont définies de manière neutre, elles ont l’apparence de données de qualité et inspirent confiance aux utilisateurs, alors même qu’elles peuvent être de mauvaise qualité.
Il arrive parfois que des données soient correctement définies mais qu’un de leur champ de définition soit « surchargé ». Cette surcharge survient lorsque des types de données supplémentaires, non destinés à ce champ, y sont implémentées.
Pourquoi ? La plupart du temps, cette surcharge survient pour éviter des améliorations coûteuses du système, ou trouver une « solution rapide » pour un problème lié à ces données.
#4 Les données redondantes et incohérentes
Les données redondantes sont toutes les données dupliquées ou accumulées et stockées dans plusieurs systèmes à des fins différentes. Ce sont des données en doublons. Ces dernières peuvent rapidement devenir incohérentes, lorsque les copies multiples de données se retrouvent avec des valeurs différentes, car les systèmes ne sont pas synchronisés.
Malheureusement, les données redondantes et incohérentes sont la norme dans la plupart des organisations. Les mêmes données dupliquées dans plusieurs systèmes vont forcément devenir un problème, leur cycle de vie n’étant pas le même. Au bout d’un certain temps, ces données n’auront plus la même valeur, alors même qu’elles seront identifiées comme similaires.
Les données redondantes coûtent très cher à l’entreprise, elles créent une dette technique. Chaque donnée dupliquée existant dans un autre système nécessite un logiciel supplémentaire pour la saisie, le déplacement ou la manipulation. Enfin, il y a aussi les coûts de maintenance, pour prendre en charge les éléments de données redondants.
Prendre une décision commerciale critique en se basant sur un doublon de donnée non mis à jour est très risqué pour l’entreprise.
La mauvaise qualité des données peut avoir d’énormes conséquences sur l’entreprise. L’étendue du rayon d’action de données non fiables, leur coût et leur impact peuvent faire de gros dégâts. Continuer dans ces conditions n’est pas une option satisfaisante, il faut avoir des responsables data (Chief Data Officer, Data Quality Manager ou Data Steward) qui s’occupent de ces problèmes dans l’entreprise, et s’équiper des bons outils, à commencer par un Data Catalog !
Pour corriger ces problèmes de Data Quality, il faut mettre en place une solution de Data Management, pour cataloguer vos données et vos métadonnées et être en mesure d’utiliser des informations fiables pour améliorer la prise de décision, condition indispensable pour construire de véritables data products à valeur métier.
Conséquences de la mauvaise qualité d’une base de données
-
Perte de confiance dans les systèmes internes.
-
Risque réglementaire : RGPD, BCBS 239, Solvency II, HIPAA.
-
Décisions stratégiques biaisées.
-
Explosion des coûts liés à la correction et au retraitement.
-
Dette technique grandissante.
La mauvaise qualité des données peut freiner une transformation digitale, compromettre la mise en place de l’IA et réduire considérablement le ROI des projets data.
Comment améliorer la qualité des données ?
-
Mettre en place une gouvernance des données
-
Définir les rôles : Chief Data Officer, Data Quality Manager, Data Steward.
-
Établir des standards et processus de validation.
-
-
S’équiper des bons outils
-
Data Catalog pour inventorier, documenter et contextualiser les données.
-
Solutions de Data Management pour monitorer et corriger la qualité.
-
Outils d’observabilité des données pour détecter rapidement les anomalies.
-
-
Former et sensibiliser les équipes
-
Développer une culture data-driven.
-
Mettre en avant les bénéfices business concrets de la Data Quality.
-
-
Mettre en place des indicateurs de suivi
-
Mesurer le niveau de qualité (taux d’erreur, taux de complétude, duplication).
-
Définir des objectifs d’amélioration continue.
-
Exemple pratique : le rôle du Data Catalog
Un Data Catalog permet de :
-
Centraliser toutes les sources de données.
-
Standardiser définitions et métadonnées.
-
Éviter la duplication et améliorer la traçabilité.
-
Donner aux utilisateurs un accès rapide à des données fiables.
C’est l’outil incontournable pour restaurer la confiance et garantir la conformité.
FAQ
-
Comment devenir Data Quality Manager ?
-
Expérience en data management, maîtrise des outils qualité et gouvernance, compétences en management et communication.
-
Quels outils peuvent améliorer la Data Quality ?
-
Plateformes de gouvernance des données (Data Governance Platforms)
Solutions de Data Observability pour détecter les anomalies et le Data Drift
Outils de gestion de métadonnées (Metadata Management Tools)
Moteurs de validation automatique pour appliquer des règles de format et de cohérence -
Quelles sont les principales causes de la mauvaise qualité d’une base de données ?
-
La mauvaise qualité des données peut avoir de multiples origines :
👉 Erreurs humaines – fautes de saisie, incohérences lors de la collecte, doublons créés par manque de process.
👉 Absence de gouvernance – quand aucun cadre clair (règles, rôles, contrôles) n’est défini, les données dérivent et perdent leur fiabilité.
👉 Systèmes non synchronisés – plusieurs outils qui stockent les mêmes données mais ne se mettent pas à jour en temps réel entraînent incohérences et redondances.
👉 Définitions incomplètes ou imprécises – sans métadonnées claires et standardisées, les données perdent leur contexte et sont mal interprétées.
👉 Héritage technologique – des bases obsolètes ou mal intégrées (legacy systems) génèrent une dette technique qui alimente la dégradation de la qualité.
👉 Croissance rapide du volume de données (Big Data) – plus les données s’accumulent, plus il est difficile d’assurer leur validation et leur nettoyage sans outils adaptés. -
Quels métiers sont responsables de la Data Quality ?
-
Le Chief Data Officer définit la stratégie, le Data Quality Manager supervise les processus, et les Data Stewards veillent au nettoyage et à la cohérence des données.
-
Quels sont les risques de non-conformité liés à la Data Quality ?
-
Des sanctions financières et réputationnelles en cas de violation du RGPD, de HIPAA ou d’autres réglementations sectorielles.
-
Quelle est la différence entre quantité de données et qualité de données ?
-
La quantité (Big Data) augmente le volume exploitable, mais seule la qualité garantit des décisions fiables et une réelle valeur business.
Points clés à retenir
- La mauvaise qualité des données génère coûts, inefficacité et risques réglementaires
- Les problèmes majeurs : inexactitude, perte de contexte, redondance, absence de définitions
- Une gouvernance solide et des rôles dédiés sont indispensables
- Le Data Catalog est l’outil central pour améliorer la Data Quality
- Investir dans la qualité des données, c’est investir dans la performance et l’IA-ready governance





