
Passionnée par la transformation de la complexité des données en clarté, Jessica Sandifer est une gestionnaire de contenu expérimentée qui conçoit des histoires qui résonnent auprès d'audiences techniques et commerciales. Chez DataGalaxy, elle crée des messages de marketing de contenu et de produit qui démystifient la gouvernance des données et rendent la préparation à l'IA réalisable.
Comment modéliser son glossaire ? L’approche par verticaux de données
28 septembre 2020 │ Lecture : 7 mins │ Culture data par Jessica Sandifer, Tech writer

- De quelles données dispose-t-on sur nos fournisseurs?
- Quelle est la différence entre un prospect et un client ?
- Comment être sûr de la formule de calcul de cet indicateur?
Si comme moi vous avez entendu ces questions de manière récurrente, il y a des chances que vous caressiez l’idée de fabriquer votre glossaire de données!
Vous vous êtes peut-être même posé la question “Pourquoi alors qu’on entend parler partout de l’importance des données, je ne dispose pas encore d’un référentiel me permettant de les comprendre”.
Lors de mes premières tentatives de construction d’un glossaire, plusieurs défis me sont apparus : identifier et définir les objets à cartographier, contextualiser les objets… mais le plus complexe était de savoir comment construire une modélisation qui s’affranchisse de la réalité technique et donne une vision fonctionnelle faisant sens pour les utilisateurs.
Cet article s’adresse à ceux qui voudraient se lancer dans l’aventure de la modélisation d’un glossaire. Il a pour vocation d’étudier les avantages et inconvénients de deux approches de modélisation d’un glossaire.
Résumé introductif
Modéliser son glossaire est une étape essentielle pour transformer les données de l’entreprise en un véritable actif stratégique. Deux approches principales s’offrent aux organisations : la modélisation par verticaux de données et l’approche orientée urbanisation. La première privilégie la hiérarchisation par domaines métiers, tandis que la seconde s’appuie sur les principes d’architecture d’entreprise pour relier les données aux processus et aux systèmes. Dans cet article, nous explorons ces méthodes, leurs avantages et leurs limites, afin de vous aider à bâtir un glossaire robuste, compréhensible et évolutif.
Pourquoi modéliser son glossaire de données ?
Un glossaire de données permet de structurer et harmoniser le langage métier dans l’organisation. Il répond à des questions récurrentes telles que :
- Quelles données possédons-nous sur nos fournisseurs ou nos clients ?
- Quelle est la différence entre un prospect et un client ?
- Comment définir la formule de calcul d’un indicateur clé ?
Sans un glossaire clair, chaque département risque de produire sa propre version des définitions, ce qui génère confusion, redondance et perte de temps.
En savoir plus sur la différence entre glossaire et dictionnaire de données
Approche par verticaux métiers : une modélisation simple et rapide
Si la première question de cet article vous a interpellé, il y a de fortes chances pour que cette approche vous parle. En effet, elle vise à définir au mieux les grands objets gérés par l’organisation : employé, fournisseurs, article.
Cette méthode consiste à rattacher hiérarchiquement les termes métiers à des domaines organisationnels (fournisseurs, clients, activités, articles, etc.).
Exemple : pour le domaine « fournisseur », on peut définir les contacts associés via des objets comme nom du commercial, email, contrat, etc. Chaque donnée est placée dans un arbre hiérarchique rattaché au domaine principal.

Avantages
- Indépendance par rapport aux systèmes : la donnée est décrite sans dépendre d’un logiciel.
- Clarté organisationnelle : chaque département (finance, ventes, achats) peut rattacher ses objets métiers.
Limites
La capacité d’appréhension pour des utilisateurs habitués à réfléchir en termes de silos applicatifs.
La gestion des objets connexes : Comment décrire les liens entre les différents concepts, ou tout simplement comment décrire la relation entre un prospect et un client ? Sans parler de la gestion des synonymes…
Bonne pratiques pour développer et maintenir vos data products
Dans ce guide, nous vous proposons une présentation complète afin de vous aider à faire face aux complexités du développement et du maintien de data products.
Téléchargez le livre blanc
Approche orientée urbanisation : une modélisation complète et systémique
Complexité pour gérer les objets connexes (ex : relier prospect et client).
Inspirée de l’urbanisation des systèmes d’information, cette approche mobilise les architectes d’entreprise pour relier le glossaire aux couches d’architecture métier, fonctionnelle et technique.

Les quatre couches principales
- Architecture métier : cartographie des processus (ventes, support, opérations).
- Vision fonctionnelle : description des fonctionnalités SI.
- Vision applicative : regroupement des briques logicielles (CRM, ERP, outils BI).
- Vue technique : éléments techniques (bases de données, flux, API, traitements).
Chaque donnée peut ainsi être décrite selon son rôle dans l’organisation et dans les systèmes.
Avantages
- Vision plus fine des dépendances entre processus et applications.
- Possibilité de tracer les liens transverses (ex : un indicateur financier utilisé dans plusieurs métiers).
Limites
- Approche plus lourde et technique, qui demande l’implication d’équipes IT.
- Risque d’une rigidité accrue si la modélisation est trop exhaustive.
Les 3 KPI pour générer une réelle valeur
Découvrez rapidement les trois meilleures façons de mesurer le succès et de faire une réelle différence dans votre organisation.
Téléchargez le livre blancComment choisir la bonne méthode de modélisation d’un glossaire ?
Lorsque vous décidez de modéliser votre glossaire, posez-vous les questions suivantes :
- Quelle est la maturité data de votre organisation ?
- Souhaitez-vous avant tout simplifier la communication métier ou structurer le SI ?
- Avez-vous besoin d’un glossaire rapide à déployer ou d’un modèle complet et évolutif ?
Dans la pratique, de nombreuses entreprises adoptent une démarche itérative : commencer par les verticaux métiers pour embarquer rapidement les équipes, puis enrichir avec une cartographie orientée urbanisation.
Bonnes pratiques de data governance pour modéliser son glossaire
- Impliquer les métiers dès le départ (finance, marketing, opérations).
- Standardiser les définitions avec des règles claires pour éviter les doublons.
- Documenter les liens entre objets métiers (prospect ↔ client, produit ↔ contrat).
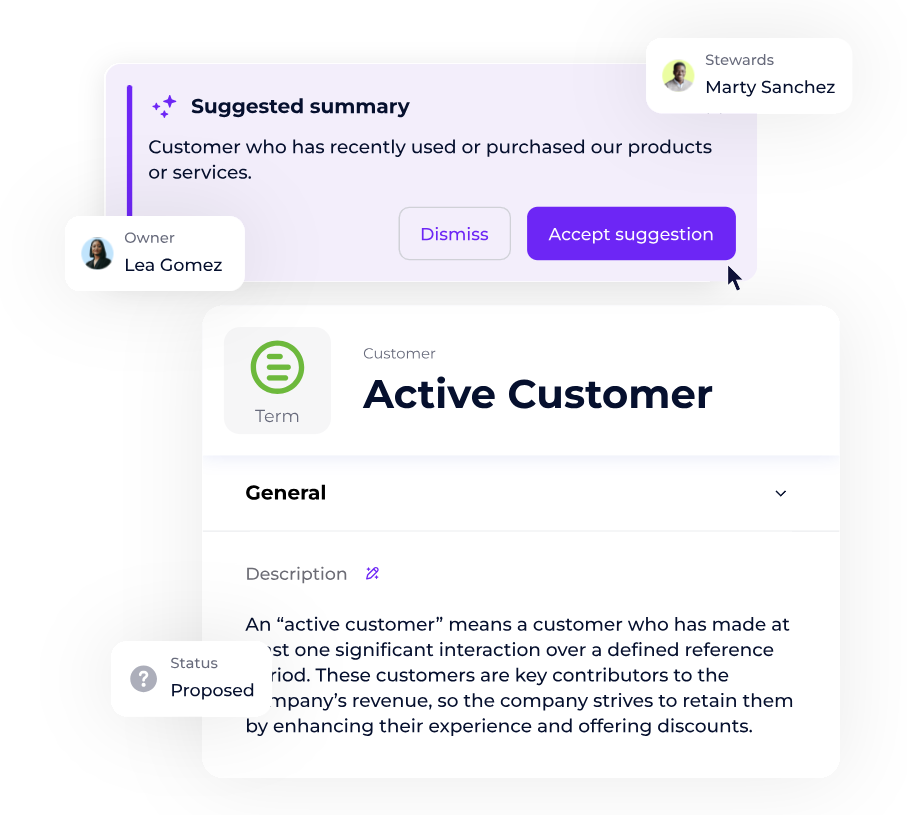
- Assurer la gouvernance : le glossaire doit être validé et maintenu par un Data Governance Manager ou un Data Steward.
- Mettre à jour régulièrement pour refléter l’évolution des systèmes et processus. Cette pratique est essentielle dans toute démarche de gouvernance des données. Pour aller plus loin, vous pouvez consulter ce guide de référence qui détaille les cadres méthodologiques et bonnes pratiques en gouvernance des données
Cas d’usage concrets : conformité, IA et qualité des données
- Conformité réglementaire (RGPD, BCBS 239, Solvabilité II) : un glossaire permet de prouver que les définitions des données sensibles sont alignées et auditées.
- Projets d’IA et d’analytique : sans glossaire, les algorithmes risquent d’exploiter des définitions incohérentes.
- Amélioration de la qualité des données : un glossaire centralisé réduit les erreurs et augmente la confiance des utilisateurs.
FAQ
- Quelle est la différence entre un dictionnaire de données et un glossaire métier ?
-
Le glossaire métier définit les concepts business (ex. : client, commande), tandis que le dictionnaire détaille les données techniques associées (ex. : champ “customer_id”, format, source).
- Faut-il un outil dédié pour modéliser son glossaire ?
-
Oui, un outil de Data Governance ou Data Catalog facilite la structuration, l’alignement avec les systèmes et la mise à jour continue.
- Quelle approche choisir pour débuter ?
-
La plupart des organisations commencent par les verticaux métiers, plus simples et compréhensibles, avant d’évoluer vers l’urbanisation.
Points clés à retenir
- Modéliser son glossaire est indispensable pour aligner métiers et IT.
- Deux méthodes existent : par verticaux métiers ou orientée urbanisation.
- La première est simple et rapide ; la seconde plus complète mais plus lourde.
- Une démarche hybride et itérative permet de concilier efficacité et exhaustivité.
- Le glossaire est un pilier de la gouvernance des données et de la conformité réglementaire.
Articles liés

Le marché de la data observability : acteurs, tendances et perspectives (2025)
La fiabilité et la transparence des données sont devenues essentielles pour toutes les organisations. En 2025, le marché de la data observability connaît une croissance fulgurante, passant d’une adoption de niche à une nécessité stratégique pour les entreprises. Cet article explique ce qu’est la data observability, pourquoi elle est indispensable, les grandes tendances qui façonnent […]
Data owner vs. data steward : rôles, différences et complémentarité
Le data owner est le responsable stratégique et décisionnaire sur les données, tandis que le data steward en est le garant opérationnel de la qualité et de la conformité. Le premier définit la vision, les règles et l’usage des données dans l’entreprise ; le second veille à ce que ces règles soient respectées et que les données restent fiables. […]
Qu’est-ce que le DataOps ?
Le DataOps, contraction de data operations, est une discipline émergente à l’intersection du DevOps et de la data science. Elle combine méthodologies agiles, automatisation et collaboration interfonctionnelle pour fluidifier l’ensemble du cycle de vie des données. En éliminant les silos entre data engineers, data scientists, équipes IT et métiers, le DataOps permet aux entreprises de […]
Développer une culture data en entreprise (2025)
Data-centric, culture data driven, pilotage par la données… Mais de quoi parle-t-on ? Avant de parler de « gouvernance des données » (on peut le faire en même temps ?), il faut accompagner l’adoption par votre entreprise d’une culture data. Pourquoi est-elle aussi importante dans une entreprise ?
Le glossaire de données, quelles différences avec le dictionnaire ?
Au début de nombreuses réflexions d’exploitation, d’optimisation ou de valorisation des données se trouve bien souvent une démarche de cartographie.
En effet, comment bien gérer un élément dont on ne sait évaluer le volume ou la complexité ?
Comment DataGalaxy Portfolio se connecte à Jira pour structurer les initiatives data au-delà de la simple gestion de tickets
Jira est omniprésent dans les équipes data modernes. Il soutient les méthodes agiles, gère les backlogs, suit les anomalies et structure l’exécution des projets. De nombreuses organisations l’utilisent également pour piloter les tâches de gouvernance des données, les problèmes de qualité, les demandes d’accès et les initiatives analytiques. Mais voici le problème : Jira est […]