
Do you know the top three modern data observability solutions for modern data teams?
Data observability solutions provide teams with real-time visibility into the health, quality, and lineage of their data, enabling them to catch issues before they break dashboards, degrade ML models, or mislead decision-makers.
In this blog post, we’ll define what data observability is, why it matters, share best practices, compare three leading data observability tools, and explain why DataGalaxy is the ideal hub to unify observability with governance, lineage, and business context.
What is data observability?
Data observability is the practice of continuously monitoring the health and reliability of data as it moves through pipelines, storage, and downstream tools.
Data observability enables teams to fully understand and monitor the health, quality, lineage, freshness, schema, and volume of data as it flows through their data stack.
It focuses on data-specific signals, such as freshness, volume, distribution, schema, and lineage, often cited as the “five pillars,” which indicate the trustworthiness of your data assets.
Why do my teams need data observability?
Build & maintain trust in your business
Bad data triggers wrong decisions, inaccurate KPIs, and broken customer experiences. Observability detects and flags anomalies before stakeholders do.
Time savings
Automated monitoring, lineage, and alerting slash the time your team spends detecting incidents and anomalies.
Operationalizing
CDEs
Do you know how to make critical data elements (CDEs) work for your teams?
Get your go-to guide to identifying and governing critical data elements to accelerate data value.

Risk reduction
As AI becomes operational, observability must track data integrity to prevent drift, hallucinations, or poisoning.
Increase scalability
As you add sources, transformations, and domains, observability ensures that quality coverage grows with your data landscape without requiring manual configuration of every table.
Performance improvement
Pinpointing inefficient queries keeps both reliability and cost in check.
Data observability best practices
1) Start with the critical data elements
Identify the tables and datapoints that power your most-used executive dashboards, customer experiences, or ML features.
2) Monitor across the five pillars
As mentioned above, your data observability should account for loss of data freshness, volume drops or spikes, distribution anomalies, schema changes, and lineage impacts
3) Add business context and ownership
Alerts are only useful when they’re actionable.
Connect tables to business definitions, owners, and domains so incidents route to the right people with the right context.
A data catalog and business glossary are key here.
4) Treat AI and LLM outputs as first-class citizens
Your data observability should cover model inputs and outputs, monitor drift and quality, and surface risks
5) Integrate with governance, lineage, and change management
Observability is most effective when alerts carry lineage context, link to owners, and respect policies
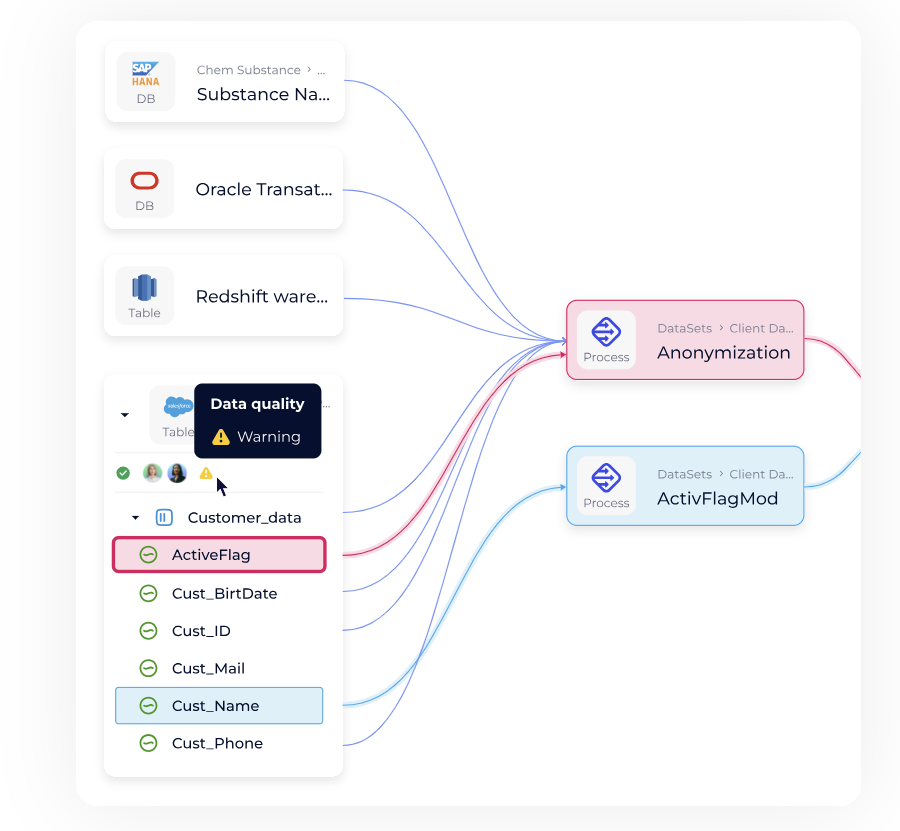
Automated data lineage
DataGalaxy gives you real-time, column-level lineage across systems, pipelines, and dashboards. No delays. No silos. Just complete visibility into how data flows, who owns it, and what it impacts.
The top 3 data observability solutions for modern data teams
There are many data observability solutions on the market, each with its own strengths and weaknesses.
Here are three options that cover a range of needs from enterprise automation to developer-friendly ops and metric monitoring.
Monte Carlo
What is it? Monte Carlo is a data observability pioneer that positions its platform as a center for “Data + AI Observability,” covering data assets, code, and AI model outputs end-to-end.
Key capabilities
- ML-powered monitoring across freshness, distribution, volume, schema, and lineage
- Deep integrations with modern stacks and visibility into performance for warehouse queries, dbt models, DAGs, and datasets
- Strong incident workflows with alerting, triage, and lineage-aware root cause analysis
Best for: Enterprises seeking broad coverage and AI-era reliability across complex, multi-domain environments where correlating incidents to code and performance is essential
Bigeye
What is it? Bigeye focuses on automation, precision, and integrations across the modern data stack, arguing that purpose-built observability beats homegrown tooling, especially as AI adoption expands.
Key capabilities
- Automated monitoring and anomaly detection aligned to enterprise reliability needs
- Emphasis on combining adaptive, AI-driven detection with traditional rules to handle a broad range of quality issues.
- Guidance and point of view on how observability and data quality are converging in 2025, with tooling designed to integrate cleanly into existing stacks.
Best for: Organizations seeking a mature, purpose-built platform with strong automation for high-scale reliability and a clear roadmap for AI-era monitoring
Why DataGalaxy is the best data observability platform for all your needs
Data observability pays off when it’s connected to governance, lineage, ownership, and semantic clarity.
DataGalaxy excels here: it acts as the central nervous system of your data landscape. It works by mapping metadata across sources, pipelines, and BI layers, and enriching it with business definitions and roles.
That makes DataGalaxy the ideal foundation to activate and operationalize your data observability practice.
Unify observability with a living data map
DataGalaxy ingests and maps metadata from your stack, exposing end-to-end, column-level lineage. This way, when an observability tool raises an anomaly, your team can instantly see upstream jobs, downstream dashboards, and accountable owners.
Add business meaning and clear ownership
With a business glossary and collaborative catalog, teams can attach semantics, definitions, and responsibilities to assets.
This helps your data observability alerts to gain context (e.g., which KPI or domain is at risk), speeding triage and communication across data, analytics, and business stakeholders.
Integrate your observability stack
DataGalaxy connects to 70+ tools across warehouses (including the Snowflake data platform), BI, ETL, and quality/observability systems. This allows you to centralize metadata and align monitoring with governance policies.
These integrations enable usage analysis, classification, and lineage to flow alongside observability signals.
Active metadata to reduce time-to-insight
Search, discovery, and relationship views (like ERDs) help practitioners resolve incidents faster and ship reliable changes sooner.
This turns active metadata into operational reliability gains.
CDO Playbook: Driving Value Through Governance from Day One
Get the inside secrets for creating a roadmap for quick wins, addressing real user needs, improving productivity with data, and connecting business goals to data challenges.

Observability built into the platform & best-of-breed partnerships
DataGalaxy prioritizes observability monitoring within its catalog experience, while pairing governance with specialized observability vendors such as Bigeye for comprehensive coverage.
This approach enables you to standardize context centrally while utilizing focused tools for detection and incident management.
Built for modern teams
DataGalaxy is designed to be intuitive and collaborative so that stewards, engineers, analysts, and business users work from the same source of truth.
Compared with complex legacy tooling, this lowers adoption friction and gets more people participating in data reliability.
The bottom line: If you think of observability as your sensors, DataGalaxy is the control center where you coordinate response, understand impact, and drive continuous improvement across data and AI use cases.
How does a data catalog and business context supercharge observability?
Even the most sophisticated data observability solutions can only go so far without context:
- What does this table mean?
- Who owns it?
- Which KPI does it feed?
- What’s the downstream impact of a schema change?
A modern data catalog solves that by centralizing business definitions, ownership, and lineage so incident responders know where to look and what matters most.
DataGalaxy’s platform combines a collaborative data catalog, business glossary, and real-time lineage in one hub.
The result is a shared, searchable system of record for data meaning and impact: exactly the context your observability alerts need to become actionable.
How to choose the best data observability solution for your team
Use the criteria below to align the available data observability tools on the market with your exact needs. Your organization’s data maturity model will also shape which capabilities to prioritize: teams in early stages may focus on basic freshness and volume monitoring, while mature organizations tackle schema drift, AI observability, and cross-domain lineage.
- Coverage & scaling: Can the platform automate monitors across thousands of tables and keep up with growth?
- Root cause speed: Does it connect anomalies to upstream jobs/models and warehouse performance?
- AI readiness: Can it observe data feeding AI/LLM systems and help monitor model-output reliability?
- Explainability & alert quality: Are alerts contextual and explainable?
- Ecosystem fit: Do integrations align with your warehouse, orchestrator, and BI stack?
- Team workflows: Will engineers and analysts actually use it? Look for collaborative workflows, clear ownership, and catalog integration to make incident response routine rather than heroic.
Putting it all together: Data observability solutions
The data era has shifted from building pipelines to operating them with confidence. That demands data observability solutions that can detect issues early, pinpoint root causes fast, and keep analytics and AI dependable at scale.
Monte Carlo, Bigeye, and DataGalaxy illustrate how the category has matured: combining rules, AI-driven anomaly detection, and performance-aware insights.
Yet observability reaches full value only when it’s connected to context, including lineage, ownership, and business meaning, so that teams can act decisively.
DataGalaxy provides that connective tissue: a collaborative data catalog and glossary with end-to-end lineage, active metadata, and integrations across your stack (including quality/observability tools).
If observability is your early-warning system, DataGalaxy is the command center that turns signals into reliable, governed, and trusted data day after day.
FAQ
-
What is data lineage?
-
Data lineage traces data’s journey—its origin, movement, and transformations—across systems. It helps track errors, ensure accuracy, and support compliance by providing transparency. This boosts trust, speeds up troubleshooting, and strengthens governance.
-
Why is data lineage important?
-
Data lineage is important because it provides visibility into the origin, movement, and transformation of data. It enables regulatory compliance, faster root-cause analysis, improved data quality, and trust in analytics. By mapping data flows, organizations enhance transparency, streamline audits, and support accurate, AI-driven decisions, making it a cornerstone of effective data governance.
-
What is DataGalaxy?
-
DataGalaxy is a modern data & AI governance platform that centralizes metadata, data lineage, and business definitions to create a shared understanding of data across the organization. Designed for collaboration, we empower teams to find, trust, and use data confidently. Learn how DataGalaxy accelerates data-driven decision-making at www.datagalaxy.com.
-
What types of systems can DataGalaxy integrate with?
-
DataGalaxy connects with a wide range of systems including data warehouses, BI tools, data lakes, ETL platforms, and governance frameworks. Supported platforms include Snowflake, BigQuery, Tableau, Power BI, dbt, Talend, Collibra, and many more. Whether your ecosystem is cloud-based or hybrid, DataGalaxy provides flexible integration paths.
-
How do you improve data quality?
-
Improving data quality starts with clear standards for accuracy, completeness, consistency, and timeliness. It involves profiling, fixing anomalies, and setting up controls to prevent future issues. Ongoing collaboration across teams ensures reliable data at scale.
At a glance
- Data observability ensures data health, quality, and lineage across pipelines, enabling teams to detect issues early and maintain trust in analytics and AI outputs.
- Leading solutions like Monte Carlo, Bigeye, and DataGalaxy combine automation, anomaly detection, and business context to deliver reliable, explainable observability at scale.
- DataGalaxy stands out as the command center for observability—unifying governance, lineage, metadata, and ownership to make every alert actionable and every dataset trustworthy.

